
This is the third issue in the series and the first one about shaping the graph: How ArchiMate derivation rules actually get built, what OWL handles and what it hands off to SHACL, and what the engine produces when validation files run.
What ArchiMate Does Well
There is a passage in Section 3.6 of the ArchiMate 3.2 specification that most practitioners read past without stopping. The spec calls it “Abstraction in the ArchiMate Language” and frames it as a description of modeling conveniences. I want to suggest it is something MUCH more profound than that.
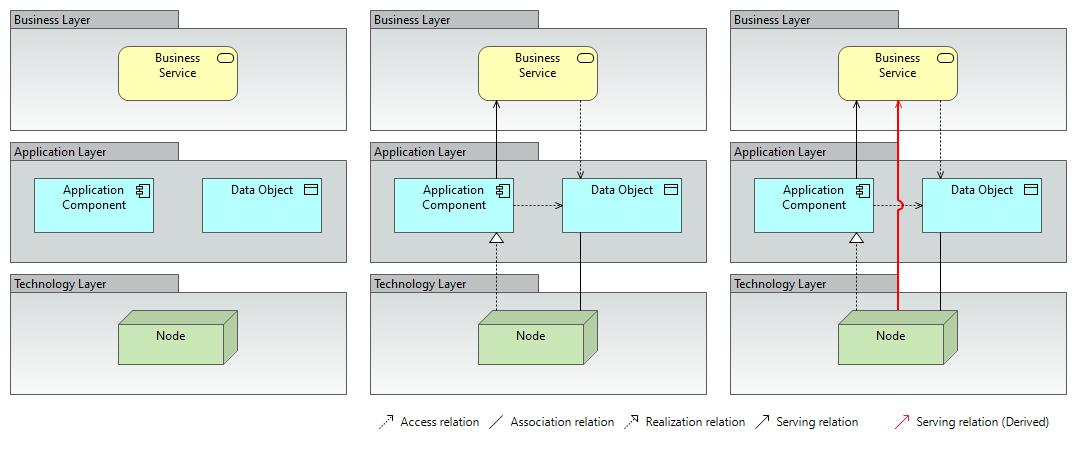
At the left side of the diagram above there are four elements, three layers, nothing connecting them. A BusinessService sitting alone in the Business Layer. An Application and a DataObject in the Application Layer. A Node in the Technology Layer. This is a legitimate ArchiMate view… a black-box view, showing the pieces without showing what is inside of them or how they relate, if they relate at all. An architect working at the right level of abstraction for the right stakeholder might draw exactly this and the interpretation would be that these are four isolated elements, four black boxes. You can’t tell anything more about each of them.
In the middle, the white box view. Now the relationships tell us the story: Application element accesses the DataObject element. The Application realizes the BusinessService. The Node realizes the Application. The DataObject is associated with the Node. The relationships are all there — structural, dependency, dynamic — each one semantically precise. The pattern is completely understandable. Abstraction is doing a lot of work.
And then there is the right view with the red line: a derived relationship running from the Node directly to the BusinessService. Even if the architect didn’t draw that connection. Even if it was never in the model. We can still infer, that the Node serves the BusinessService, because ArchiMate’s derivation rules tells us exactly what kind of relationship it is, without the architect making any explicit assertions about its existence.
That red line is the point of this post.
No Other Modeling Language Does This
ArchiMate’s relationships have formal semantics.
Three people that look at an ArchiMate diagram, see different things.
An executive might see colored boxes and lines, but they are all black boxes. Very little meaning.
A systems architect sees architecture facts or decisions which they’ve seen before. They navigate the diagrams from years of practice, filling in what the diagram omits because they already know or are familiar with the underlying context of what the omitted detail implies.
An ArchiMate expert or a seasoned knowledge engineer sees something rarer. The red line. Something an architect would have traced by hand, but didn’t — here, it’s where the natural language specification, that produces the preconditions for inference –the derivation rules– fill in the gaps. A language where the red line, is not something an ArchiMate practitioner has to do to fill the gap — it is an implied conclusion that follows precisely because of what was explicitly stated. That is not common. In the landscape of modeling languages, it is nearly unique.
They are ALL make different interpretations, despite the fact that they are looking at the same thing.
These abstraction mechanisms are core to the architect toolkit. Every experienced ArchiMate practitioner not only navigates this stack constantly: zooming up and down between layers of concerns, going in and out on levels of abstraction, deciding how much of the white box to show and to whom. The black-box view is not an incomplete model. It is a deliberate one. But deliberate abstraction has a cost. When you show only the black box and omit the relationships beneath it, a human reader might follow you. They might understand that detail exists even when it isn’t drawn. A machine does not. A repository that only stores what was explicitly asserted goes blind the moment you abstract. The connections between elements at different layers of concern simply aren’t there.
This is what derivation rules solve. The ArchiMate metamodel takes the tacit navigational knowledge that practitioners carry, everything an experienced architect understands about how abstraction levels relate, which structural relationships imply which dependencies, how dynamic behavior propagates through a realized stack, and makes it explicit as formal rules. Named relationship types. Defined combination logic. The implicit work the architect’s mind does when reading a black-box view becomes something the engine can do instead. The architect abstracts freely. The repository stays coherent.
That red line on the right side of the diagram is not a guess. It is a derivation. The result of the engine following the chain of explicit relationships and concluding that the Node validly connects to the BusinessService through a (derived) Serving relationship. The architect does not need to draw every consequence, because the rules derive them and the engine realizes them.
The question this post answers is how I turned that red line, those derivation rules, into code.
ArchiMate’s Relationships Are Logical Commitments
The architect already knows that realization is not the same as serving. You use them differently without thinking about it. Realization flows upward through layers. A technology element implements an application element. Serving creates a dependency without structural coupling. An application serves a business process, but doesn’t own it. You learned this in practice, applied it in models, corrected others who conflated them. It felt like craft knowledge.
It is also a formal logical property.
The knowledge engineer needs to see this clearly: ArchiMate’s specification doesn’t just name its relationship types — it defines what they mean in a way that has logical consequences. Realization flows upward through layers, never downward. Assignment links active structure to behavior. Serving creates a dependency without structural coupling. These are not prose descriptions. They are architectural commitments with consequences that can be followed, chained, and reasoned over.
The architect reads this as confirmation of something they already knew. The knowledge engineer reads it as something rare: a natural language specification that already did the ontological work. The semantics don’t need to be imposed from the outside. They are in the standard. The formalization is a translation, not an invention.
The Four Questions No Other Language Answers
For a language to support inference over relationships, its specification needs to answer four questions — inside the language, not in a tool, a convention, or a practitioner’s memory.
What does this relationship mean? Not a name and a prose gloss, but a precise architectural claim with logical weight. The architect answers this question implicitly every time they choose one relationship type over another. The knowledge engineer needs it answered in the spec, formally enough to encode.
Where is it valid? ArchiMate’s Appendix B contains over 3,800 element-relationship-element validity rules. The architect experiences these as the grammar of the language. The sense that something is wrong when a BusinessObject appears as the subject of an assignment. The knowledge engineer needs that grammar written down precisely enough to enforce it, not as folklore, but as a constraint.
How does it combine with others? When a structural relationship chains into a dependency relationship, what follows? The architect navigates this constantly when tracing impact across layers. The knowledge engineer needs the combination logic in the specification, and ArchiMate provides it, in a defined cluster taxonomy with explicit rules for every cross-cluster combination.
What is its strength relative to others of the same kind? Composition implies more than aggregation, which implies more than assignment, which implies more than realization. The architect knows this ordering. The knowledge engineer needs it as something queryable, a property of the relationship type itself, defined in the specification, not inferred from convention.
No other major modeling language answers all four questions in the specification itself:
- TOGAF — names its relationships but defines no combination logic and no derivation rules
- UML — has a
«derive»stereotype, a marker that says “this could be derived,” but specifies no mechanism, no rules, no strength ordering - SysML — adds parametric constraints on properties but nothing equivalent to “chain a structural relationship with a dependency and derive the result”
- BPMN — defines execution semantics for process flows but not derivation across relationship types
ArchiMate answers all four, for all eleven relationship types, in a form that is both human-readable and machine-executable. The same specification serves both readers, because it was precise enough to serve both.
The Taxonomy the Architect Uses and the Knowledge Engineer Encodes
In Post 2, I showed how I encoded ArchiMate’s relationship types — structural, dependency, dynamic, and specialization — in RDF-Star. In this post, I’ll show how I encoded ArchiMate’s derivation rules, as listed in Appendix C of the specification. These rules are normative — not optional guidance, but part of what a conformant implementation of an ArchiMate licensed product is expected to support. Here, the relationship types become the grammar the derivation engine matches against, because the rules are written in terms of these categories, not individual types.
Structural relationships — assignment, aggregation, composition, realization — define ownership, composition, and implementation chains. The architect uses them to show how the architecture holds together. The knowledge engineer sees a cluster with a defined strength ordering and a set of combination rules that govern what structural chains imply.
Dependency relationships — serving, access, influence, association — capture how elements use or affect each other without structural coupling. The architect uses them to show operational surface and exposure. The knowledge engineer sees a second cluster with its own strength ordering, directional constraints, and cross-cluster behavior.
Dynamic relationships — triggering, flow — express process causality and transfer. The architect uses them to show behavioral logic and sequence. The knowledge engineer sees the substrate for the most nuanced derivation rules — the ones where boundary conditions matter and transitivity cannot be declared globally.
Specialization stands alone, governing the entire profile and inheritance mechanism. The architect uses it every time they extend the language for a domain. The knowledge engineer declares it owl:TransitiveProperty — one line, infinite depth, no recursion to write or maintain.
This taxonomy is not new to the architect. It is the structure they have been working within for years, often without naming it. What is new is seeing it also as a formal grammar, one that has been there in the specifications for almost 20 years, waiting to be encoded.
The Payoff
Derivation rules are only possible when relationships have formal semantics to reason over. You cannot build a consequence system on top of labels that carry no logical weight. The red line in that diagram — the connection that no architect drew, but that follows necessarily from the ones they did — is the result of a language that answered all four questions above, in the specification, for both readers at the same time.
The ArchiMate specification made an investment that no other modeling language made. The four-cluster taxonomy, the validity matrix, the combination principle, the strength ordering — all of that work is what makes Appendix C possible. The twenty derivation rules are not a feature added on top. They are a consequence of how the language was designed from the inside.
The ArchiMate architect always knew the red line was true.
The knowledge engineer can now prove it.
What “Reasoning” Actually Means
In Post 1, I argued that RDF’s open-world semantics and URI-based identity make it the right substrate for EA. In Post 2, I showed the ontology files: elements, relationships, and the separation between semantics and constraints. In this post, I explain the mechanism: what actually happens when an engine processes the graph, and why different engines produce different results.
Enterprise Architecture tools are often sold on “reasoning” as a vague promise. Intelligent systems that will surface hidden insights from your architecture repository. My thesis is that the ArchiMate Ontology is more specific and, in some ways, more useful than any existing tool can actually promise.
How RDF Engines Reason
An RDF graph, at rest, is inert. A collection of triples. Subject, Predicate, Object. The BusinessActor class sits there. Its rdfs:subClassOf declarations point to ActiveStructure, to BusinessLayer, to Element. Nothing happens when data is at rest. The Data is immutable. Until an engine processes it.
What happens when an engine does process the RDF graph, depends entirely on which kind of engine, and under what rules.
The W3C has standardized several entailment regimes, formal specifications of what an RDF engine is permitted to infer from a graph, given different vocabularies and rule sets. The simplest is plain RDF entailment: the engine only accepts what is explicitly stated. Load a graph, get back exactly what you put in. No surprises, no inferences. This is how most triple stores behave by default, and it is the right behavior when you want raw data.
RDFS entailment adds a layer. An RDFS-aware engine knows that rdfs:subClassOf is transitive, that rdfs:domain and rdfs:range allow type inference, that if :actor1 rdf:type archimate:BusinessActor and archimate:BusinessActor rdfs:subClassOf archimate:ActiveStructure rdfs:subClassOf… then :actor1 rdf:type archimate:Element follows — not because you said it, but because the RDFS rules guarantee it. The engine materializes that triple. It is now in the graph, available to any query, as if you had asserted it yourself.
OWL entailment goes further. OWL 2 is built on a formal logical foundation that guarantees completeness: every inference the ontology implies will be found, and the reasoner will always terminate. It won’t chase an infinite chain or silently miss a consequence. That guarantee is what makes OWL the right substrate for encoding the ArchiMate language itself. An OWL engine processes not just subclass hierarchies but property axioms: transitivity, symmetry, inverse properties, cardinality restrictions, equivalence declarations. The class of inferences it can make is substantially larger than RDFS, and the guarantees are formal. If the ontology says archimate:specialization is an owl:TransitiveProperty, the engine does not need a rule that says “follow two-hop specialization chains.” Transitivity is the rule, stated once, applied universally, for any depth.
Compare this to how a Labeled Property Graph engine works. Neo4j, TigerGraph, Amazon Neptune in LPG mode, these are exceptional database engines. Give them a graph and a Cypher or Gremlin query, and they will navigate millions of nodes and edges with remarkable speed. But they do not reason. They traverse.
When you write a Cypher query that (:ApplicationComponent)node has a [:REALIZES] relationship to a (:BusinessService) node, the engine finds the edge and returns the connected node. It does not know that REALIZES implies directionality by layer. It does not know that an ApplicationComponent is an ActiveStructure unless you labeled it that way explicitly. It does not know that a constraint valid for all ActiveStructure elements should apply here. It knows what you told it, and it retrieves what matches the pattern you asked for.
If you want an LPG to enforce that realization only flows upward through layers, you write that check yourself, in the Application, in a stored procedure, in a constraint you maintain, update, and enforce outside the database. The semantics live outside the graph. The graph is just data, shaped in a different way.
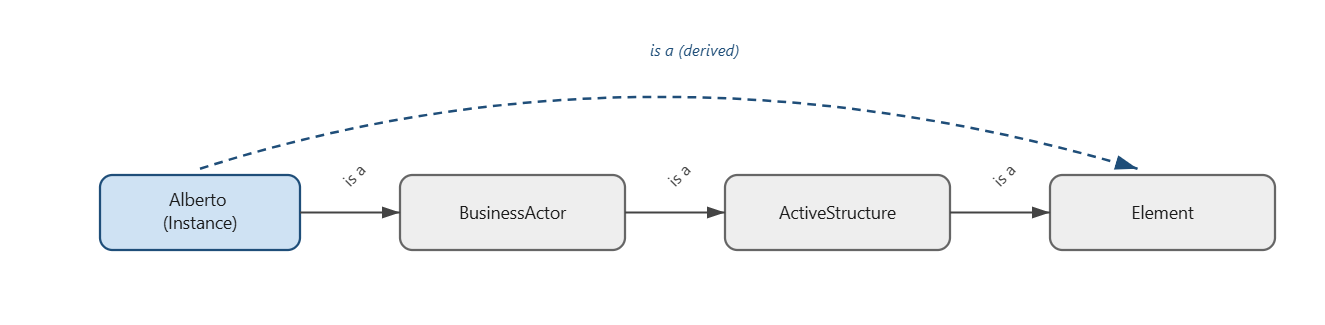
An RDF engine with OWL entailment works differently. The semantics live inside the graph, encoded as axioms. When you declare that myOrg:Alberto is an archimate:BusinessActor, you are not labeling a node, you are placing that instance inside a formal class hierarchy, and the engine draws every consequence that follows. myOrg:Alberto is a BusinessActor. BusinessActor is a subclass of ActiveStructure. ActiveStructure is a subclass of StructureAspect. StructureAspect is a subclass of Element. The engine materializes all of it, without being asked. A SHACL shape written against archimate:ActiveStructure fires on myOrg:Alberto automatically, because the entailment regime guarantees the subclass chain is real, not just a naming convention.
This is the difference between a graph that stores architectural knowledge and one that holds it. An LPG is not automatically a “knowledge database”, they are just databases that whose data happen to have a graph shape. An RDF graph with OWL reasoning holds implicit knowledge… knowledge that was never explicitly asserted but that follows necessarily from what is explicitly asserted. The BusinessActor instance carries its layer, its aspect, its element type, and everything that entails, without anyone having to write those facts down individually for every node in every model.
The tradeoff is real and worth naming. LPG traversal is fast and operationally straightforward. OWL reasoning introduces computational overhead, and the cost scales with the complexity of the axioms and the size of the graph. For simple property graphs representing social networks or recommendation engines, that tradeoff makes no sense. For a system where the entire point is that the language has formal semantics that should be machine-enforceable, it was not the tradeoff. It was the requirement.
But OWL reasoning has a scope, and knowing where it ends matters as much as knowing what it does. A reasoner propagates what is entailed by the ontology’s axioms — class hierarchies, property declarations, logical constraints. It does not look at data patterns. It does not materialize new relationships based on what combinations of triples exist in a model. For that, you need a different mechanism entirely.
This is where SHACL Advanced Features sh:construct rules enter. They are not inference in the OWL sense. They are pattern-triggered graph construction: match these triples, produce these new ones. Deterministic. Data-driven. Run against whatever the graph contains at execution time. The derivation engine is built from these rules — not from OWL axioms — because derivation is about what follows from a specific model, not about what is true of the language in general.
Three regimes. OWL for the language. SHACL-AF for the data. SPARQL to query both.
Recall the file structure from Post 1. The ontology ships in two folders: Ontology and Validation. The Ontology folder holds archimate.ttl and archimate_skos.ttl — the entire ArchiMate language encoded in OWL: class hierarchies, property declarations, semantic axioms, and human readable taxonomy. The Validation folder holds the SHACL constraint files. And archimate_derivation_rules.ttl — which lives in the Validation folder but is a distinct file from the constraint shapes — holds something that sits between the two: not language semantics, and not validation rules. It is what tells the engine how to imply from what was never explicitly stated. This is where Ontology meets Knowledge Engineering.
The ArchiMate 3.2 specification defines twenty derivation rules in Appendix C, split into two categories. Valid derived relationships, which I’ve labeled DR1 through DR8, what the specification guarantees follows logically from the asserted model. And Potential derived relationships, PDR1 through PDR12. The potential aspect can be subjective, it depends on the specifics of the model concerned. Nonetheless, the distinction is not cosmetic. A valid derivation is an architectural fact. A potential derivation is an architectural “it depends”. Both belong in the graph. They must not be indistinguishable from each other, or from what was explicitly drawn. This is what archimate:confidence is for, and why it lives on the relationship edge rather than in a separate table. Can Potential derivations be more defined? Assertive? Yes… BUT… for this project, I’m looking at fidelity to the specification. Anything further, wouldn’t be ArchiMate.
The Grammar the Rules Run On
In Post 2, I showed how I encoded ArchiMate’s relationship types — structural, dependency, dynamic, and specialization — in RDF-Star. In this post, I’ll show how I encoded ArchiMate’s derivation rules, as listed in Appendix C of the specification. These rules are normative — not optional guidance, but part of what a conformant implementation is expected to support. Here, the structural and dependency relationship types become the grammar the derivation engine matches against — the rules are written in terms of these categories, not individual types. Dynamic relationships and specialization play by different rules, as I’ll show.
The relationship types, encoded as OWL hierarchies:
archimate:structuralRelationship → assignment, aggregation, composition, realizationarchimate:dependencyRelationship → serving, access, influence, associationarchimate:dynamicRelationship → triggering, flowarchimate:otherRelationship → specialization
Every derivation rule matches against rdfs:subPropertyOf+ archimate:structuralRelationship and similar patterns — not against archimate:composition directly. This means the rules work correctly for any relationship in the cluster, including relationships added by future profile extensions. The grammar does not need updating when the vocabulary grows.
Within the structural cluster, the ArchiMate specification imposes an ordering. When two structural relationships combine into a derived one, the result is the weaker of the two. Weakness is formalized as a queryable numeric property:
archimate:realization deriv:structuralStrength 1 .archimate:assignment deriv:structuralStrength 2 .archimate:aggregation deriv:structuralStrength 3 .archimate:composition deriv:structuralStrength 4 .
The same pattern applies to the dependency cluster:
archimate:association deriv:dependencyStrength 1 .archimate:influence deriv:dependencyStrength 2 .archimate:access deriv:dependencyStrength 3 .archimate:serving deriv:dependencyStrength 4 .
composition is the strongest structural relationship — it implies shared lifecycle, the whole and its parts inseparable. realization is the weakest — it says something implements something else, without structural ownership. A chain of composition(a,b) and realization(b,c) yields realization(a,c). The stronger relationship does not propagate. The weaker one does. This is the specification’s principle, and the BIND(IF(?strength1 <= ?strength2, ?rel1, ?rel2) AS ?weakerRel) pattern in the SPARQL CONSTRUCT implements it directly.
DR 2 and PDR 7 rely on relationship strengths for derivations. As seen below.
DR1 – Transitivity of Specialization
When I first seriously looked at RDF, this is the moment that stopped me.
One line:
owl:TransitiveProperty .
This is when it hit me. No rules. No recursion. No inheritance. No query to remember to write. No stored procedure to maintain. No join table. No application logic that breaks the next time someone adds a level to the hierarchy. I can simply declare that specialization is transitive. That if A specializes B, and B specializes C, the engine knows A specializes C. No special artifacts. It is just there. For any depth. For any model. Embedded in the language.
This is what makes taxonomies possible. And ArchiMate, at its core, beneath the diagrams and the notation, is a taxonomy. Layers. Aspects. Element types arranged in a hierarchy of increasingly specific concepts. The transitivity of specialization is not a feature of this ontology. It is a feature of what ArchiMate is.
For an analyst, this is not a minor detail. It is the thing analysts do all day long. Abstraction. Generalization. The recognition that a specific thing is an instance of a more general category, which is itself an instance of a more general category still. A cell phone, is a mobile device, which is a device, which is a node, on a network. ArchiMate is built on this, the entire layer and aspect hierarchy, the specialization relationship, the profile mechanism, all of it assumes that classification chains are transitive by nature. That is not a modeling convention. It is a logical fact about what classification means.
Every other tool I had worked with made me program that fact. Cypher lets you write archimate:specialization+ to traverse a chain at query time, but you have to remember to write it, and it only works on edges already in the graph. A relational database gives you recursive CTEs. Both require you to encode transitivity as a procedure every time you need it. The knowledge that specialization is transitive lives in your head, not in the system.
In OWL, it lives in the system. Declare it once, in the schema, as a fact about what the property is — and the reasoner carries it everywhere, into every query, every validation shape, every derived relationship. You do not ask for it. It is simply true, and the engine knows it.
DR1 is just that. Transitivity of Specialization. Declared in OWL
archimate:specialization rdf:type owl:TransitiveProperty .
DR2–DR8: The Engine Running
All seven valid derivation rules follow the same structural pattern. Once you understand one, the rest are variations on the same grammar.
DR2 — Structural chain. Two structural relationships in sequence: structural(a,b) and structural(b,c). The derived relationship connecting a to c is the weaker of the two source relationships. A BusinessActor composed into a BusinessCollaboration, and that collaboration realizing a BusinessProcess, yields an assignment between actor and process — not a composition, not nothing. The weakest valid connection that the chain supports.
DR3 — Structural into dependency. A structural relationship (a,b) followed by a dependency relationship (b,c) yields the same dependency relationship (a,c). If a Node realizes an ApplicationComponent, and that component serves a BusinessProcess, then the node serves the business process — by transitivity through the structural link. The dependency carries forward. The structural relationship does not.
DR3 is the rule that produces the red line from the opening diagram. Here is the actual SHACL-AF rule from archimate_derivation_rules.ttl:
<#DR3_StructuralDependency> rdf:type sh:SPARQLRule ; rdfs:label "DR3: Structural + Dependency → Dependency" ; sh:prefixes <#> ; sh:construct """ CONSTRUCT { ?a ?depRel ?c . <<?a ?depRel ?c>> archimate:confidence "valid" ; archimate:description "Derived via DR3: structural + dependency" ; deriv:derivedFrom ?structRel, ?depRel . } WHERE { ?a ?structRel ?b . ?b ?depRel ?c . ?structRel rdfs:subPropertyOf+ archimate:structuralRelationship . ?depRel rdfs:subPropertyOf+ archimate:dependencyRelationship . FILTER(?a != ?c) FILTER NOT EXISTS { ?a ?depRel ?c } } """ .
Walk through it line by line. The WHERE clause finds any chain where element ?a has a structural relationship to ?b, and ?b has a dependency relationship to ?c. The rdfs:subPropertyOf+ pattern matches against the cluster, not the individual type — so realization, composition, aggregation, or assignment all qualify as ?structRel, and serving, access, influence, or association all qualify as ?depRel. The two FILTER lines prevent self-relationships and skip derivations that already exist in the graph.
The CONSTRUCT clause materializes the result: a new dependency relationship ?a ?depRel ?c, carrying the same type as the original dependency. The RDF-Star annotation stamps it with archimate:confidence "valid", the rule that produced it, and the two source relationships it was derived from. A later SPARQL query can distinguish this edge from one an architect drew, trace it back to the relationships that produced it, and filter by confidence level.
That is the entire rule. Twenty lines. It handles every combination of structural-into-dependency across all element types, all layers, including relationships added by future profile extensions, because the cluster grammar does the matching. No case statements. No lookup tables. The specification’s combination logic, executable.
DR4 — Structural opposing a dependency. A structural relationship (a,b) and a dependency from a third element c into b. If c depends on b, and a structurally owns b, then c depends on a. The dependency propagates upstream through the structural chain. This is where impact analysis becomes non-trivial: a dependency on a component is implicitly a dependency on everything that component composes, aggregates, or realizes.
DR5 — Structural into dynamic. A structural relationship (a,b) followed by a dynamic relationship (b,c). The dynamic relationship carries forward: a triggers or flows into c through b. A SystemSoftware node assigned to a TechnologyService, and that service triggering a TechnologyProcess, means the system software is part of the triggering chain.
DR6 — Flow opposing a structural relationship. A structural relationship (a,b) and a flow from some c into b. The flow carries forward to a. If b composes a, and c sends a flow to b, then conceptually c is sending a flow toward a. The structural containment makes the upstream element reachable.
DR7 — Triggering followed by structural. A triggering relationship (a,b) and a structural relationship from b into c. The triggering carries forward: a triggers c. The structural relationship on the target end does not change the causality — if a triggers what b structurally owns or realizes, a triggers it.
DR8 — Triggering transitivity. Two triggering relationships (a,b) and (b,c) yield triggering(a,c). Unlike specialization — which is handled by OWL via owl:TransitiveProperty — triggering is not declared transitive in the ontology. The reason is that triggering transitivity has boundary conditions that specialization does not: it should not chain across domain boundaries in the same way, and the derivation rules enforce those boundaries explicitly through the cross-domain restriction shapes. Handling it as a SHACL-AF rule keeps the constraint machinery in one place.
Every rule materializes the derived relationship with the same provenance structure:
<<?a ?weakerRel ?c>> archimate:confidence "valid" ; archimate:description "Derived via DR2: structural relationship chain" ; deriv:derivedFrom ?rel1, ?rel2 .
The quoted triple is the relationship. The annotations are the receipts. The deriv:derivedFrom property names which two source relationships produced it. A later SPARQL query can ask not just “what is connected to what” but “what connections were explicitly drawn, and what was inferred from what.”
PDR1–PDR12: The Honest Maybe
The potential derivation rules are a different epistemic category. The specification defines them as relationships that might be valid — worth surfacing for human review, not safe to assert as architectural facts.
PDR1 through PDR4 handle the specialization dimension: what relationships does a specialized element potentially inherit from its generalizations, and vice versa. A Person profile that specializes BusinessActor — and that BusinessActor has an assignment to a BusinessProcess — might also have that assignment. Or might not. It depends on whether the specialization is intended to inherit the relationship or carve out an exception. The derivation surfaces the possibility; the architect decides.
PDR5 and PDR6 are the reverse-direction analogues of DR3 and DR4 for dependency relationships: structural combinations with dependencies where the direction is inverted from what DR3 and DR4 handle. The specification treats these as potential rather than valid because the inverse direction introduces more ambiguity about whether the relationship actually holds.
PDR7 is dependency chain transitivity: two dependency relationships in sequence yield a potential dependency between the endpoints. Two serving relationships, or a serving feeding into an access, potentially implies a dependency from the source to the final target. It is potential rather than valid because dependency chains can cross domain and layer boundaries in ways that do not always produce meaningful architectural facts.
PDR8 through PDR11 extend the dynamic relationship patterns in directions where the spec considers the result plausible but not guaranteed. PDR12 is the grouping derivation: relationships involving Grouping elements potentially propagate to the grouped elements, because a grouping is a convenience boundary, not a structural one.
All twelve potential rules materialize with archimate:confidence "potential" instead of "valid". In SPARQL, filtering on confidence becomes a governance control:
SELECT ?source ?target ?rel ?rule WHERE { ?source ?rel ?target . <<?source ?rel ?target>> archimate:confidence ?conf ; archimate:description ?desc . BIND(STRAFTER(STR(?desc), "Derived via ") AS ?rule) FILTER(?conf IN ("valid", "potential"))}ORDER BY ?conf ?rule
Run this against a model after the derivation engine has fired, and you get two things: a complete map of what was derived and why, and a natural triage — valid derivations you can act on, potential ones you need to review.
Cross-Domain Restrictions: Where the Grammar Has Borders
The derivation rules above operate within a domain-agnostic grammar. But the ArchiMate specification, in Section B.4, imposes explicit restrictions on which derived relationships are permitted to cross domain boundaries. These are not soft recommendations. They are normative restrictions, and they interact with the derivation rules in ways that most EA tools quietly ignore.
The restriction logic is: certain domain pairings restrict which relationship types can cross. Implementation & Migration into Motivation: only assignment, realization, influence, association. Motivation outward into Core or Strategy: only association. Strategy into Core: only association. The pattern is that as you move further from the Core layers — into motivation or implementation concerns — the permitted relationship types narrow to the least-committing ones.
These are enforced in archimate_derivation_rules.ttl as a sh:NodeShape with a SPARQL sh:select that fires against the full set of elements after derivation. The shape catches any derived relationship that violates the domain crossing restrictions and surfaces it as a SHACL violation — not a warning, a violation. A derived relationship that passes DR3’s pattern logic but crosses a restricted domain boundary is not valid. The cross-domain restriction overrides the derivation rule.
This is where the two mechanisms interact. The SHACL-AF construct rules materialize derived relationships into the graph. The SHACL validation shapes then run against those materialized relationships alongside the asserted ones. Derivation and validation are not the same pass. They are sequential: derive first, validate after.
Where the Ceiling Is
There is something this system cannot do. It is worth naming plainly, because it is a fundamental expressiveness limit, not a tooling gap. No amount of RDF-Star or SHACL-AF addresses it.
ArchiMate elements can function simultaneously as part and whole. A Node composes SystemSoftware and is itself composed into a data center. A BusinessProcess is a subprocess of a larger process and simultaneously decomposes into smaller ones. This is the holon pattern — entities that are simultaneously part and whole — and it is native to systems thinking and to EA practice.
RDF-Star lets you annotate a relationship as a first-class fact. An employment relationship, for example, can be expressed as a quoted triple with its own governed properties:
<< myModel:AlbertoMendoza archimate:assignment myModel:ITConsultantRole >> myModel:organization myModel:OneITConsultingLLC ; myModel:startDate "2020-01-01"^^xsd:date ; myModel:contractType "Principal" ; myModel:email "alberto@oneitcs.com"^^xsd:anyURI .
This is useful and governed. But the annotated triple itself cannot be typed as a class instance, cannot be the target of a sh:class constraint, and cannot itself be the subject of a derivation rule. You can describe the employment relationship. You cannot yet reason over it as a first-class governed entity — the way you can reason over AlbertoMendoza or ITConsultantRole. That is the ceiling. The holon pattern requires that a relationship between parts can itself become a whole. RDF-Star annotation approaches that, but does not fully instantiate it. RDF 1.2’s rdf:reifies primitive is the path toward closing that gap — but that is future work.
What Gets Built
Running this system against a real ArchiMate model produces a graph that contains three kinds of facts:
Asserted facts — what an architect explicitly drew. These carry archimate:confidence archimate:Asserted, or no confidence annotation if they predate the metadata convention.
Valid derived facts — what the specification guarantees follows from the asserted model. DR2–DR8 have fired, the cross-domain restrictions have been checked, and what remains carries archimate:confidence "valid" with full derivation provenance.
Potential derived facts — what the model suggests might follow, pending human review. PDR1–PDR12 have fired, and the results carry archimate:confidence "potential" with the rule that produced them.
A compliance audit queries across the first two categories. An architecture review surfaces the third category as a structured agenda — not a list of unknowns, but a list of specific architectural questions the model raises and the derivation engine cannot answer.
The graph is larger than what was drawn. It contains receipts for everything that was inferred, and it is honest about what it does not know. That combination — complete, provenance-carrying, and epistemically calibrated — is what separates an architecture repository that reasons from one that merely stores.
That extra computation is the tax we pay with RDF. Every materialized derivation, every entailment the reasoner propagates, every SHACL-AF rule that fires — it costs cycles that an LPG never spends, because an LPG never tries. Whether that tax is worth paying depends on what you need the repository to do. If you need it to answer questions it was never explicitly asked… if you need that red line, then it is not a tax. It is the price of admission.
Next post: Profiles and Specializations. How the triple inheritance pattern and owl:TransitiveProperty on specialization combine with the derivation engine to enable domain-specific extensions of the language — without touching the core ontology.






Leave a comment