
An independent formalization of the ArchiMate 3.2 specification as an RDF/OWL ontology with SHACL validation. This is the first issue of a series on why Enterprise Architecture practice could use a fundamentally different information system model.
TL;DR
The Semantic Web was built for software agents. Machines that could traverse structured knowledge and reason over it on your behalf. The technology that it produced: URIs, RDF, OWL, SPARQL, turns out to be exactly the foundation Enterprise Architecture never had and always needed.
Therefore, I am formalizing ArchiMate 3.2 as an RDF/OWL ontology: all 61 element types, all 11 relationship types, the full class hierarchy, and the metadata that shapes them. SHACL validation shapes enforce the specification’s relationship matrix by construction, not by convention. Derivation rules materialize inferred relationships directly into the graph. And because every resource is URI-addressed, domain experts can contribute what they know from their own systems without surrendering ownership. The full picture emerges without anyone having to own all of it. And the best part, the part that changes everything: a graph that can reason over itself. Where questions that were technically answerable but practically impossible: impact analysis, compliance scope, architectural provenance, all become accessible, on demand, to both humans, and AI agents.
This post covers the motivation, an analysis of the current state of the EA practice and the tooling that currently supports it, an intro to my solution and the key design decisions behind the implementation.
The Problem – Diagrams are Flat
I want to start with the three problems that drove this work, because they’re more interesting than the technical part. Why I believe most Enterprise Architecture tools have been failing to support the practice.
Problem one: The diagrams should be alive
Enterprise Architecture frameworks like TOGAF, DoDAF, and FEAF have long used ArchiMate as their lingua franca. Pick any established EA tool: Archi, iServer, BiZZdesign, Sparx EA… and you will find rich, color-coded diagrams: blue boxes for technology, yellow for business, green for application. Relationships flow between layers. Architects work on them furiously and meticulously. Stakeholders nod Sometimes approvingly. Sometimes with hesitation. And then the meeting ends, the diagrams are flattened, saved as a PDF, and the knowledge it took so long to collect gets effectively frozen, ending up on the proverbial shelf.
The next time the board meets, new facts have surfaced, a decision needs revisiting, someone asked a question about impact. The diagrams are now months old. Nobody can dig into them, nobody trusts them. The insights that were once readily available have evaporated. And the expert who knows the domain best is in the room… but can’t answer because, he “would have to go and check”.
ArchiMate is not just a drawing standard. It’s a formal language with precisely defined element types and relationship semantics. Knowledge distilled into a simple, understandable model and even simpler views. Treating it like a repository of diagrams is like printing out a database and calling it a solution. ArchiMate was designed for more than this. We just haven’t been treating it that way.
Problem two: the repository should answer questions on demand
“If this technology node fails, what business services are affected?” That’s not an exotic question. That’s the most basic impact analysis an EA team should be able to answer before lunch. In practice it means opening a tool, manually tracing relationships across diagrams, and hoping the model is current. The data is there. The connections are there. But the underlying storage is relational — and the query is a fragile recursive CTE across a schema that bears no resemblance to the architectural concepts you’re trying to traverse. Technically possible, practically inaccessible.
Now add a compliance audit. An auditor asks which systems are in scope for PCI-DSS, which applications touch the payment flow, which services they depend on, which network segments they sit on. Or a HIPAA review: where does protected health information live, what systems touch it, what are the access paths. Or SOX: which applications support financial reporting, what changed, who approved it, when. These are not exotic questions. They are the questions that determine whether your organization passes or fails an audit. And the honest answer, in most EA practices today, is: “I’d have to go and work on it.”
The data is there. The connections are there. The knowledge was captured, painstakingly, in the model. But a diagram cannot be queried. It cannot reason. It cannot surface what it knows unless a human traces it by hand. The architecture repository should be more than a filing cabinet with good graphic design. It should be queryable, reasoned with, and capable of producing insight on demand. Like an LLM, but for your architecture.
Problem three: the system should match how the organization actually works
The expert knows his domain. IT knows their domain. Leadership knows theirs. Neither has the full picture, and there’s no technical mechanism to link these domains without someone building and maintaining a pipeline between them. Ah!… we need an EA, we need the tools, we need the frameworks… Here comes the EA, riding the elevator, up and down, left and right, binder full of diagrams under his arm, suitcase full of skills, both hard and soft, on the other hand, brain full of institutional memory. A wizard, a toll, a risk. The reality? Most institutions don’t have one. They have many! The lead analyst in each business unit, the ERP architect in central IT, the boss with the spreadsheet paying for the shared services, and gaps between them all that no one diagram will ever close.
The model should reflect how the organizations actually work: distributed, federated, owned in parts. Not because centralization is wrong, or pure decentralization exists, but because it is the normal way we actually organize and scale. What’s needed is a technical mechanism that lets each domain contribute what it knows, links those contributions through shared identifiers, and surfaces the full picture without demanding that any one person or team own all of it. A web of knowledge.
The Tools Failed The Practice
Early EA frameworks were essentially document-based. TOGAF gave us a structured workflow — the ADM — to think about architecture and how it all connects, created as if EA was a linear narrative: start here, build requirements, go around the circle, produce diagrams, meet back here with all of the requirements and diagrams, start the cycle again. Documenting and diagramming was the rage.
ArchiMate, developed in the Netherlands in the mid-2000s and later adopted by The Open Group, was looking to formalize the architect’s language on these diagrams with precisely defined element types, layered concerns, and relationship semantics that actually meant something. All elements then could be stored in a model that could be governed, referenced, and evolve over time rather than recreated from scratch in every engagement. The EA Repository, a managed information system of architecture artifacts, became the ambition. ArchiMate was the language to fill it. The exchange file was born, and tool vendors had a brand they could sell.
But classical EA tools stored this information in relational tables. In a relational model, you need junction tables to represent many-to-many relationships, foreign key constraints to enforce referential integrity, and complex joins to traverse even shallow relationship chains. A query like “find all elements reachable from this BusinessActor through assignment and serving relationships across layers” becomes a recursive CTE. Brittle, expensive, and hard to maintain. If it’s a one-time question, you’ll never get the answer. Not because it’s impossible, but because it cost more to produce, and no-one was willing to pay for drip by drip insights.
Relational databases were simply inadequate for this problem, so the tools were… inadequate for the practice. Centralized. Clunky. Narrow. The whole field suffered. The EA became a roadblock instead of an enabler. The dreaded Ivory Tower was born.
This is not a critique of ArchiMate. This is a limitation of the underlying technology of the time, and a limitation that shaped the entire practice around it.
Graphs Were the Obvious Fix
ArchiMate models are, at their heart, graphs. Elements are nodes. Relationships are edges. Aspects and layers are classification hierarchies. This structure is a natural fit for graph representations.
But it wasn’t until the early 2010s that graph databases became mainstream. They started getting recognized as real database solutions mainly driven by social networks, the ICIJ Panama Papers site, fraud detection algorithms, and recommendation engines. Neo4j became the first popular, production-ready native property graph database.
So by the mid-2010s, things started changing in the EA tooling landscape. LeanIX launched as a cloud-native app. BiZZdesign launched Horizzon, fully hosted and SaaS-based. Both using graph engines to power their EA repositories.
Graph over relational was the obvious correction. EAs got a breather. But what most people reach past without noticing is that Neo4j was not the only graph in the room. While the EA tooling world was converging on property graphs, the semantic web community had spent two decades solving a different problem entirely… a web designed not for human readers but for machines. Software agents that could traverse structured knowledge and reason over it on your behalf. The infrastructure they built to solve that problem — URIs, RDF, OWL, SPARQL — turns out to be exactly the foundation EA never had and always needed.
What LPGs Can’t Tell You
LPGs operate under a closed-world assumption: what is not stored is absent. The graph only knows what was explicitly asserted. If a fact is missing, it doesn’t exist. There’s no distinction between “we checked and found nothing” and “we never checked.”
For the semantic web — and for EA alike — that distinction is not pedantic. It is the difference between a validated finding and an unknown gap. In the semantic web: 404, resource not found. In a graph: “I don’t know” is a valid, honest answer, and exactly what you need when you’re running an audit, assessing impact, or making an architectural decision under incomplete information.
LPGs are also, structurally, just another data silo. Nodes are identified by internal IDs or local string labels. There is no technical mechanism to link a node in your graph to a concept in a partner’s graph, a regulatory vocabulary, or a published capability taxonomy without building and maintaining a pipeline between them.
The Semantic Web “Resource Description Framework” (RDF) inverts both — the closed world and the silo.
The open-world assumption means that what is not known is unknown, not absent. An RDF graph with SHACL (Shapes Constrain Language) validation can produce three outcomes: conformant, non-conformant, and indeterminate. That third state matters enormously in a distributed model where no single system has complete knowledge. It’s an honest answer… and honest answers are the foundation of data you can actually trust.
URI-based identity means every RDF resource is globally addressable by design. An ArchiMate element in your model can carry a URI that an auditor’s taxonomy also references. A SPARQL query can join across both graphs using those shared identifiers. No ETL pipeline. No schema mapping. No coordination required in advance. Just URIs doing what URIs were designed to do.
What RDF Actually Buys You
Beyond the philosophical advantages, the Web Ontology Language (OWL) lets you express things about ArchiMate that an LPG simply cannot natively represent.
Class hierarchies with inference. A BusinessActor is an InternalActiveStructure, which is a StructureAspect, which is an Element. Declaring that hierarchy in OWL means a reasoner can propagate it, you don’t have to assert the full chain for every instance. Queries and validation shapes written against ActiveStructure automatically apply to BusinessActor, ApplicationComponent, and Node without modification.
Relationship semantics that mean something. composition implies a shared lifecycle; aggregation does not. realization flows upward through layers, never down. These are not just documentation conventions, they are architectural facts that should be machine-interpretable, not just things architects are expected to remember.
Executable validation. The ArchiMate 3.2 specification encodes over 3,800 element-relationship-element rules in Appendix B. With SHACL, those rules become shapes, constraints that a validator runs automatically against any model, not documentation that architects are expected to memorize and apply by hand. A model that passes is conformant by construction, not by convention.
Materialized derivation. The specification defines rules for inferring valid relationships from explicitly modeled ones — DR1 through DR8 for valid derivations, PDR1 through PDR12 for potential ones. With SHACL-AF sh:construct, those rules materialize inferred relationships directly into the graph, making derived connections available to any SPARQL query without requiring a full OWL reasoner in the query path.
Reasoning. RDF reasoning is grounded in formal semantics. It infers subclass and subproperty relationships, domains, and ranges. OWL extends this with complex axioms (e.g., equivalence, disjointness). RDF reasoners then apply entailment rules to generate all logically implied triples (often through actual materialization) storing inferred triples in the graph.
RDF/OWL was designed for exactly for rich knowledge representation. The choice is not fashionable. It is load-bearing.
…This is the stopping point for the analysis… from here on, it gets very technical. Skip ahead to Current Status if you want the summary...
Building ArchiMate in RDF
RDF graphs are built on globally addressable URIs — every prefix declaration is just a shorthand for a URI namespace. I’ll skip the boilerplate in the code samples, but if you want more grounding in RDF before continuing, this introductory video is worth the twenty minutes.
The Core Ontology
The ontology starts with a clean separation that the ArchiMate specification describes in the Specs but never formally encodes in the Exchange File: things that appear in models (Concepts) and classifiers that describe how those things are organized (Aspects and Layers).
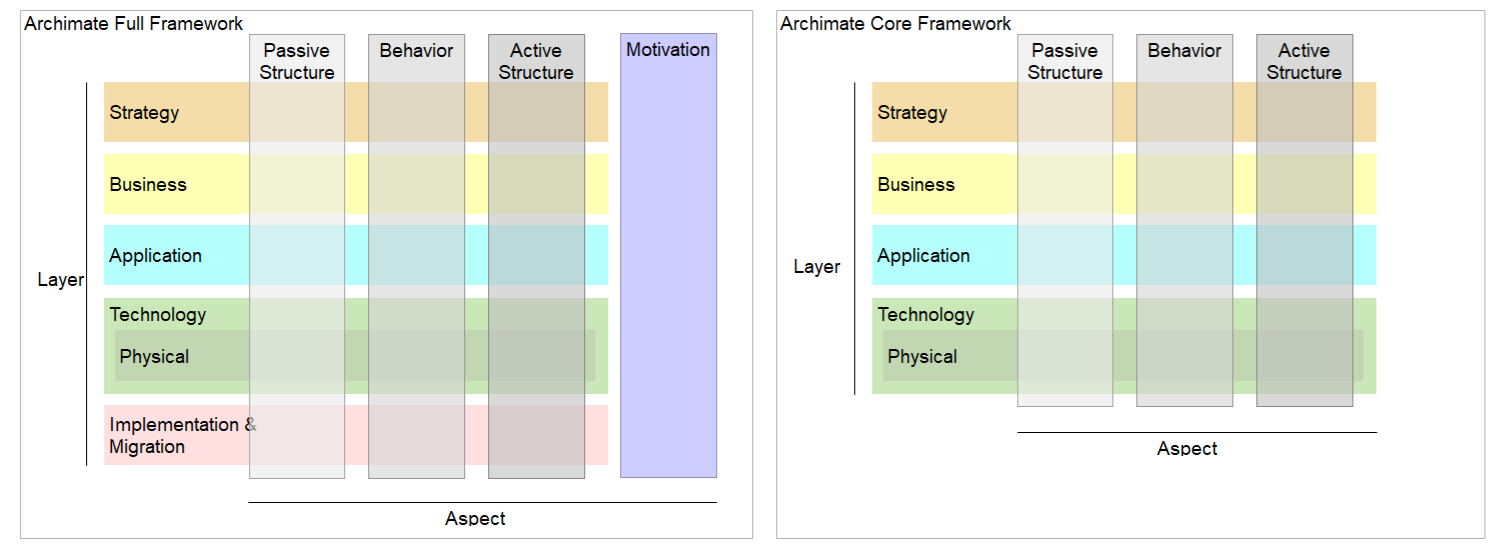
In most EA tools, this distinction collapses into a flat type system. A BusinessActor is just a table at best or a row in a table at worst. Its layer and aspect memberships are either implicit in the name or stored as separate metadata fields. With an ontology, we can categorize every element, explicitly, under all three: Concept + Aspect + Layer
ArchiMate └── Model
├── Concept ← things IN models (Elements, Relationships)
├── Aspect ← meta-classifier (structural/behavioral/motivation)
└── Layer ← meta-classifier (business/app/tech/physical/…)
The class tree defined in RDF/OWL would looks like this.
@prefix archimate: <https://purl.org/archimate#> .#### 1.0 ArchiMate General Definitions<#ArchiMate> rdf:type owl:Class ; rdfs:label "ArchiMate" ; rdfs:comment "ArchiMate Enterprise Architecture modeling language, a visual language with a set of default iconography for describing, analyzing, and communicating many concerns of Enterprise Architectures as they change over time. The standard provides a set of entities and relationships with their corresponding iconography for the representation of Architecture Descriptions." ; rdfs:subClassOf owl:Thing ;<#Model> rdf:type owl:Class ; rdfs:label "Model" ; rdfs:comment "A model contains elements and relationships within an architecture." ; rdfs:subClassOf <#ArchiMate> .<#Concept> rdf:type owl:Class ; rdfs:label "Concept" ; rdfs:comment "A conceptual entity within the ArchiMate modeling language." ; rdfs:subClassOf <#Model> .<#Layer> rdf:type owl:Class ; rdfs:label "Layer" ; rdfs:comment "A major division in the architecture that categorizes elements according to their scope and purpose." ; rdfs:subClassOf <#Model> .<#Aspect> rdf:type owl:Class ; rdfs:label "Aspect" ; rdfs:comment "Classification of elements based on layer-independent characteristics related to the concerns of different stakeholders. Used for positioning elements in the ArchiMate metamodel." ; rdfs:subClassOf <#Model> .Each one of the Aspects and Concepts are further divided into their own classes.
Aspect captures what role an element plays in the architecture. It is ArchiMate’s formalization of a simple intuition borrowed from natural language: every meaningful statement has a subject, a verb, and an object.
StructureAspect elements are the nouns — the actors, components, and nodes that exist and can perform or be acted upon. Within structure, the ActiveStructure / PassiveStructure split separates agents (things that initiate behavior) from artifacts (things that are created, accessed, or transformed by behavior). BehaviorAspect elements are the verbs — processes, functions, services, events. The Internal / External distinction within behavior is equally deliberate: Internal Behavior is what an element does; External Behavior is what it exposes to others. CollectiveBehavior captures interactions that span multiple active structure elements.
Aspect*)
├── StructureAspect
│ ├── ActiveStructure
│ │ ├── InternalActiveStructure
│ │ └── ExternalActiveStructure
│ └── PassiveStructure
├── BehaviorAspect
│ ├── InternalBehavior
│ ├── ExternalBehavior
│ └── CollectiveBehavior
└── MotivationAspect # cross-cutting — has no Layer (
Layer captures where an element lives in the architectural stack — the concern it belongs to, not the role it plays.
CoreLayer is the heart of every ArchiMate model: Business, Application, and Technology. These three layers encode the canonical separation between organizational behavior, software, and infrastructure — and the relationships between them (realization flowing upward, serving flowing across) are what give ArchiMate models their analytical power.
ExtendedLayer covers the outer concerns: Strategy for motivation and capability planning above the business layer, Physical for hardware and physical infrastructure below technology, and Implementation for migration and change management that spans the stack during transformation programs.Layer
├── CoreLayer
│ ├── BusinessLayer
│
│
└── ExtendedLayer
├── PhysicalLayer ├── StrategyLayer └── ImplementationLayer
Now it’s a just a matter of enumerating all the elements, with their respective properties, aspect and layer.
Example: BusinessActor
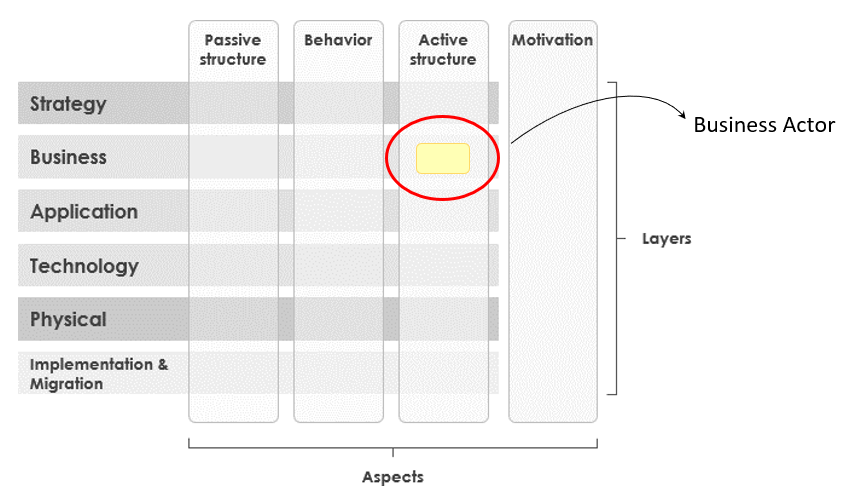
<#BusinessActor> rdf:type owl:Class ; rdfs:label "Business Actor" ; rdfs:comment "An organizational entity that is capable of performing behavior." ; rdfs:subClassOf <#Element> ; rdfs:subClassOf <#BusinessLayer> ; rdfs:subClassOf <#ActiveStructure> .Three rdfs:subClassOf declarations. That is the entire encoding of a BusinessActor‘s position in the metamodel — its type, its layer, and its aspect — expressed in a form a reasoner can propagate automatically to every instance.
* Motivation is the odd one out. It has an Aspect but no Layer — it’s genuinely cross-cutting by specification. In OWL this is just the absence of a Layer superclass. In a relational schema it’s a special case you have to handle explicitly.
Relationships
ArchiMate defines 11 relationship types, grouped into four clusters, plus a separate relationship connector mechanism. In the ontology, relationships are modeled as OWL object properties — not classes — which means they connect element instances directly as predicates in a triple. They are organized under four base properties:
structuralRelationship
├── assignment
├── aggregation
├── composition
└── realization
dependencyRelationship
├── serving
├── access
├── influence
└── association
dynamicRelationship
├── triggering
└── flow
otherRelationship
└── specialization # owl:TransitiveProperty
RelationshipConnector
└── Junction # owl:Class — typed by junctionType "and"|"or"
Each cluster encodes a distinct semantic category. Structural relationships define composition and ownership — composition implies a shared lifecycle, aggregation does not. assignment links active structure to behavior; realization connects implementation to what it realizes, flowing upward through layers. Dependency relationships capture how elements use or influence each other: serving exposes capability, access reads or writes passive structure, influence affects without formal dependency, association handles untyped connections. Dynamic relationships express process flow: triggering is causal, flow carries information, material, or energy.
specialization stands alone as the only otherRelationship — and it carries a special property worth noting: it is declared as an owl:TransitiveProperty. This means if element A specializes B, and B specializes C, a reasoner can infer that A specializes C. This is what makes profile hierarchies work — Person → BusinessActor → Element is inferrable without explicitly asserting every step.
Junction is not a relationship. This is a deliberate modeling decision. archimate:Junction is an owl:Class — a first-class element in the model, not a property. It sits under archimate:RelationshipConnector and carries a archimate:junctionType datatype property with two valid values: "and" or "or". An AND junction means all incoming relationships must be satisfied; an OR junction means at least one must be. By modeling it as an element rather than a relationship type, junctions can participate naturally in RDF-Star annotations and SHACL validation without special-casing.
Directionality is not cosmetic. realization flows upward — a TechnologyLayer element realizes an ApplicationLayer element, never the reverse. serving flows upward — a lower-layer element serves a higher-layer one. These directional constraints are enforced as SHACL property shapes at Level 2, making them machine-checkable rather than just documented conventions.
Why Relationships Are Properties, Not Classes
Readers familiar with OWL will notice something: archimate:Relationship exists as an owl:Class in the concept hierarchy, but the actual relationship types — assignment, serving, realization — are declared as owl:ObjectProperty. These two representations are never formally connected by an OWL axiom. This is intentional and needs explaining.
The class side exists for metadata inheritance. Because Relationship is a subclass of Concept, any relationship instance can carry identifier, name, and documentation — the same universal properties that elements have. That’s the only job the class does.
The property side exists for graph connectivity. OWL properties are what actually connect element instances as predicates in triples. This is how RDF works — you need a property to make a statement.
The alternative would be OWL 2 punning — declaring the same URI as both an owl:Class and an owl:ObjectProperty simultaneously, which is legal in OWL 2 DL:
<#structuralRelationship> rdf:type owl:Class ; # class side rdfs:subClassOf <#Relationship> .<#structuralRelationship> rdf:type owl:ObjectProperty ; # property side rdfs:domain <#Element> ; rdfs:range <#Element> .I considered punning but rejected it for three reasons. First, reasoner support is inconsistent — Pellet handles it, but HermiT can produce unexpected inferences. Second, SHACL already handles all relationship validation; there is no use case that requires a reasoner to infer relationship types as class instances. Third — and this is the key reason — RDF-Star already solves the metadata problem that punning would only partially address.
Relationships with RDF-Star
In a standard RDF graph, a relationship between two elements is a triple:
myOrg:StudentInformationSystem archimate:serving myOrg:StudentEnrollmentService .This works. But it loses something important: the relationship itself carries no metadata. What is the name of this relationship? When was this relationship established? By whom? Is it current, proposed, or deprecated? Was it derived? What’s the confidence level? In ArchiMate, relationships are not just connections — they are either facts or architectural decisions, and they should have provenance.
RDF-Star solves this by allowing triples to be the subject of other triples. A relationship becomes a quoted triple that can itself be annotated:
<< myOrg:StudentInformationSystem archimate:serving myOrg:StudentEnrollmentService >> archimate:id "id-123456789" archimate:name "Serves" archimate:documentation "SIS serves Student Enrollment Services" archimate:establishedBy "Alberto D. Mendoza" ; archimate:effectiveDate "2024-09-01"^^xsd:date ; archimate:status "Current" ; archimate:confidence "Valid" .The relationship still exists as a traversable edge in the graph. But now it also carries first-class metadata — queryable, validatable, and evolvable over time. This is what bridges the dual representation: the quoted triple <<s p o>> allows property-as-predicate usages to carry the same metadata that the class side was designed to hold, without reification overhead.
The SPARQL query changes accordingly — you can now ask not just “what is connected to what” but “what connections are currently active, established after a given date, with a known owner”:
SELECT ?component ?service ?establishedBy WHERE { << ?component archimate:serving ?service >> archimate:status archimate:Current ; archimate:effectiveDate ?date ; archimate:establishedBy ?establishedBy . FILTER(?date >= "2024-01-01"^^xsd:date)}This is a query that an EA team can actually use for governance — not a toy example, but a real audit of which architectural connections are current, traceable, and owned.
The Polikoff Rule, Applied
Irene Polikoff, co-founder of TopQuadrant and chair of the W3C working group that created SHACL, argued in two influential posts (1) (2) that the semantic web community had been misusing OWL for years, bending it into a validation tool it was never designed to be. Jan Voskuil coined the term: the Polikoff Rule. Basically, if you can express a data constraint in SHACL, do not try to express it in OWL. The ArchiMate ontology is structured around that rule. If you look at the project structure, the semantics files live in ontology folder. Constraints live in validation folder. (It took a few commits to get the structure right).
ontology
├── archimate.ttl # Main ontology file├── archimate_skos.ttl # SKOS vocabularyarchimate.html # Human-readable vocabulary└──
validation
├── archimate_validation_core.ttl # Level 1 validation
├── archimate_validation_metamodel.ttl # Level 2 validation
├── archimate_validation_relationships.ttl # Level 3 validation
└── archimate_derivation_rules.ttl # Derivation rules
First, OWL was designed for inference under the open-world assumption — it describes what things are and lets a reasoner derive consequences. Using OWL restrictions for validation is technically possible but semantically wrong: an OWL cardinality restriction does not mean “this property must have exactly one value”; it means “if this thing belongs to this class, it can be inferred that it has exactly one value.” The absence of that value is not a violation — it is simply unknown. Pre-SHACL, this was the only mechanism available for expressing constraints in RDF, and ontology designers bent the language to a purpose it was not designed for. SHACL, standardized by W3C in 2017, was designed specifically for validation, and changes the semantics entirely: a constraint violation is a violation, not an inference gap.
Second, Polikoff’s follow-on principle — also visible in the directory structure— is that many things called “OWL ontologies” are actually vocabularies: collections of terms with labels, definitions, and hierarchical relationships, but no schema or property constraints. These belong in SKOS, not OWL. archimate_skos.ttl holds exactly this: term definitions, alternative labels, broader/narrower relationships between concepts, the browsable structure that makes the ontology legible to architects rather than just to reasoners. The archimate.html file is generated from it — a human-readable vocabulary that requires no RDF tooling to consult.
archimate.ttl holds what OWL is actually good at: the class hierarchy, object properties, and the semantic relationships between them. What a BusinessActor is. What specialization means as a transitive property. How layers and aspects compose into a coherent metamodel. These are statements about meaning, and OWL is the right language for them.
The validation folder holds the constraints — what a valid ArchiMate model must look like, what the specification permits, what Appendix B requires. Each file is independent: a reasoner consuming archimate.ttl does not need to load the validation shapes. A governance tool running SHACL validation does not need to load the SKOS hierarchy. The separation is not just clean architecture — it is what makes the system extensible. Other organizations can import the OWL class hierarchy, layer their own SHACL shapes on top, and remain conformant with the shared semantics without inheriting constraints that only apply to one context.
The result is a model that can reason over itself and validate itself, while remaining faithful to the ArchiMate specification in all three registers: meaning, vocabulary, and constraint.
Validation Architecture: Three Levels
Appendix B of the ArchiMate spec opens with a sentence that most ArchiMate tool documentation quietly ignores: “this appendix is mainly intended for tool implementation purposes.” The implication is that the matrix is the normative floor, the thing a conformant tool must actually enforce. In practice, very few -non ArchiMate certified tools (except Archi), and reading the appendix closely makes clear why.
The relationship tables themselves are one challenge: 58 concrete element types (61 minus a few), 11 relationship types, a matrix of permitted combinations that cannot be inferred from layer or aspect membership alone. A BusinessActor composing a BusinessInterface is valid. A BusinessActor composing a DataObject is not. Both are business layer elements in the active structure aspect — the distinction only resolves at the level of exact element type against Appendix B.
But the tables are actually the easier part. Section B.4 adds 14 cross-domain restriction rules that govern when derived relationships are permitted to cross domain boundaries. Derivations involving Motivation elements can only carry Association outward; derivations from Core into Strategy are restricted to Realization and Association; derivations involving Passive Structure elements have their own separate constraint set. These restrictions apply on top of the relationship tables, interact with the derivation rules, and require tracking not just the source and target element types but the domains of all three elements in a derivation chain — including the intermediate element c that the two source relationships joined through.
The resulting validation problem is not a lookup table — it is a constraint satisfaction problem with conditional branching across element type, aspect membership, layer membership, domain membership, and derivation chain topology. Most EA tools implement a simplified approximation, typically checking direct relationships against a subset of the matrix while silently permitting cross-domain combinations that Appendix B explicitly prohibits.
The SHACL implementation encodes the full matrix for direct relationships: 58 element types across all layers, validating composition, aggregation, access, and realization — the four types where permissibility is genuinely type-specific. The remaining relationship types (flow, triggering, serving, assignment, specialization, influence, association) are handled at Level 1 or Level 2, or are universally permissive by specification. The B.4 cross-domain restrictions are enforced separately through domain-scoped shapes that fire on derived relationships carrying the RDF-Star provenance metadata from the derivation engine — which is the technical reason the derivation and validation components are designed to interoperate rather than run independently.
A model that passes Level 3 is conformant with Appendix B by construction. That is a stronger claim than most EA tooling can make.
The shackles of SHACL
The Shapes Constraint Language -SHACL- is used for validation and is structured in three progressive levels, designed for adoption rather than all-or-nothing compliance.
Level 1 — Core Validation (archimate_validation_core.ttl)
This is the foundation every model must pass before layer or relationship rules are even considered. It doesn’t care about ArchiMate semantics yet — it cares about whether the graph is structurally sound: are concepts properly identified, are composition chains acyclic, are specializations connecting the right types? Most constraints surface as hard sh:Violation; the one exception is deep specialization chains, which are flagged as sh:Info since they are not inherently invalid — just worth reviewing.
Level 1 covers four areas:
- Concept requirements: every element and relationship must have exactly one
identifier, onename, and at most onedocumentation. Identifiers are validated against a naming pattern (^[a-zA-Z_][a-zA-Z0-9_-]*$), and no two concepts may share the same identifier across the model. - Specialization integrity: specialization must connect elements of the same concrete ArchiMate type, self-specialization is prohibited, and chains of five or more levels are flagged as informational.
- Composition integrity (Sanity check): no self-composition, no circular composition chains, and composition part uniqueness — a part can belong to exactly one whole.
- Aggregation integrity (Sanity check): no self-aggregation, no circular aggregation chains.
Level 2 — Metamodel Validation (archimate_validation_metamodel.ttl)
Every shape is written in terms of abstract classes — archimate:ActiveStructure, archimate:BehaviorAspect, archimate:CoreLayer, archimate:MotivationAspect — and validates structural patterns that hold across the entire metamodel. Assignment always flows from active structure to behavior. Triggering and flow always connect behavior to behavior. Motivation elements never participate in triggering or flow. These rules are true regardless of whether you’re looking at a BusinessActor, an ApplicationComponent, or a Node; the abstract aspect × layer class hierarchy does all the work.
Level 2 encodes ten sections of metamodel figures from the ArchiMate 3.2 specification: the generic metamodel for core layers, Strategy layer patterns, core layer interface/service patterns, cross-layer realization constraints, Physical layer deviations from the generic metamodel, Implementation & Migration patterns including the deprecated WorkPackage → Deliverable realization, Motivation metamodel patterns, junction type and homogeneity validation, and RDF-Star relationship attribute constraints — validating that accessType, influenceSign, influenceStrength, and flowType carry only permitted values. That last section connects directly back to the RDF-Star design decision: metadata attached to relationships is not just queryable, it is validated.
A model that passes Level 2 is structurally sound, but it has not yet been checked against the specification’s full element-type relationship matrix.
Level 3 — Full Matrix Validation (archimate_validation_relationships.ttl)
This is where the specification’s Appendix B lookup table becomes executable code. It asks a fundamentally different question than Level 2: not “does this pattern make structural sense?” but “is this specific combination of element types permitted by the ArchiMate 3.2 relationship matrix?” A BusinessActor composing a BusinessInterface is valid. A BusinessActor composing a DataObject is not. That distinction is invisible at the aspect × layer level — both are elements in the business layer — and can only be caught by checking exact element types against Appendix B.
The file covers 58 concrete element types across all layers, validating four relationship types: composition, aggregation, access, and realization. The remaining relationship types — flow, triggering, serving, assignment, specialization, influence, and association — are intentionally excluded because they are already handled at Level 1 or Level 2, or are universally permissive by specification. This division of responsibility is what makes the three levels coherent rather than redundant: each level handles exactly the constraints appropriate to its granularity.
A model that passes Level 3 is conformant with the ArchiMate 3.2 specification by construction. A model can pass Level 2 and still fail Level 3 — Level 2 says “this assignment makes structural sense,” Level 3 says “but these two specific element types are not permitted in that relationship.”
Derivation Rules
The specification defines two sets of derivation rules: DR1–DR8 for valid derived relationships, and PDR1–PDR12 for potential derived relationships. These rules allow a reasoner to infer additional valid relationships from explicitly modeled ones.
These are implemented in archimate_derivation_rules.ttl as SHACL-AF sh:construct rules, meaning they run as graph construction queries, materializing inferred relationships into the graph rather than requiring the querying system to perform the inference at runtime. This is a deliberate tradeoff: materialization increases graph size but makes the inferred relationships available to SPARQL queries without requiring a full OWL reasoner in the query path.
This section requires a post of it’s own. So will punt the details on this one for later.
The Point of it All: Federation
This is where the architectural decisions of all of this work compound into something practically useful. And it is worth being specific about what “practically useful” means, because federation is one of those words that sounds like a feature and behaves like a consequence.
Consider three systems that currently have no formal relationship: a CMDB recording physical infrastructure, an HR system recording team membership, and an ArchiMate model recording application architecture. Each system knows something the others don’t. No single system can answer: “which team is accountable for the business service affected if this server fails?”
In a conventional integration, answering that question requires an ETL pipeline, a shared schema, a coordination meeting, and ongoing maintenance as each system evolves independently. The answer is technically available — the data exists somewhere — but the cost of surfacing it exceeds what anyone will pay for a single operational question. So the question goes unanswered, or gets answered slowly, manually, and once.
In a federated RDF architecture, the same question requires only shared URIs. The CMDB records a server with a URI. The ArchiMate model records a TechnologyNode with the same URI. The HR system records a team with a URI that appears in the ArchiMate model as an assigned BusinessActor. A single SPARQL query traverses all three graphs using those shared identifiers:
SELECT ?team ?service WHERE { # Infrastructure failure ?server a archimate:Node ; archimate:id "srv-prod-042" . # What application component runs on it? << ?appComponent archimate:realization ?server >> archimate:status archimate:Current . # What business service does that component realize? << ?appComponent archimate:realization ?service >> archimate:status archimate:Current . ?service a archimate:BusinessService . # Who owns that service? << ?actor archimate:assignment ?service >> archimate:status archimate:Current . # Cross to HR graph: who is that actor's team? GRAPH <https://hr.myorg.example/graph> { ?actor org:memberOf ?team . }}No joins. No schema negotiation. No pipeline. The answer emerges from the graph because the graph was designed to be traversed this way. The architectural content, the operational data, and the organizational data share a coordinate system — URIs — and SPARQL treats that as sufficient to query across all three.
A second example makes the compliance use case concrete. Consider a PCI-DSS audit. The auditor’s question is: which systems are in scope, what do they touch, and who approved the connections? In a conventional EA practice, this means opening the model, manually tracing relationships, cross-referencing a spreadsheet, and hoping nothing has changed since the last review. In a federated RDF model, scope can be queried directly — and because RDF-Star metadata travels with the relationships, the provenance is already in the graph:
SELECT ?system ?connectedTo ?approvedBy ?approvedOn WHERE { # Systems tagged in scope for PCI-DSS ?system archimate:complianceTag "PCI-DSS" . # What do they connect to, and through what relationship? << ?system ?rel ?connectedTo >> archimate:status archimate:Current ; archimate:approvedBy ?approvedBy ; archimate:effectiveDate ?approvedOn . # Only current, explicitly approved connections FILTER(?approvedOn >= "2024-01-01"^^xsd:date)}ORDER BY ?system ?approvedOnThis is not a toy query. It is the audit answer, produced on demand, with provenance included. Every connection is traceable to a person and a date. Every relationship that is missing an approval is surfaced as a gap rather than silently omitted. The open-world assumption does real work here: an RDF validator can distinguish between “this connection was reviewed and approved” and “this connection has no approval recorded” — two very different compliance states that a closed-world system would flatten into the same absence.
RDF-Star metadata extends this further across every use case: relationships carry provenance, timestamps, and confidence scores as first-class graph data. When an assignment was established, by whom, under what authority — all of it becomes queryable alongside the architectural content itself. The graph does not just answer questions about structure. It answers questions about the history and ownership of that structure. No diagram captures that. No relational EA repository was designed to.
What “shared URIs in practice” actually requires is worth being honest about. It does not require a centralized registry or a coordination committee. It requires agreement on namespace conventions — typically one URI per system of record, with each domain owning its own namespace — and a lightweight vocabulary alignment step when two graphs use different terms for the same concept. owl:sameAs handles the simplest cases; SKOS mappings handle the rest. The technical barrier is low. The organizational barrier — convincing each domain to expose its data in RDF — is not. That is the real integration problem, and it is the same problem every federated architecture faces. RDF does not make it disappear. It makes the technical side of it tractable enough that the organizational side becomes the binding constraint, which is where it belongs.
Current Status
The ontology is open for testing. Coverage is complete: all 61 element types, all 11 relationship types, all three validation levels, all 12 derivation rules. The permanent URI
https://purl.org/archimate#
What is not yet done is worth stating plainly, because the gaps are the more interesting part of what comes next.
Tooling for ArchiMate Exchange Format import. The ontology exists. Getting real-world models into it requires a conversion layer from ArchiMate’s XML exchange format to RDF/Turtle. This is straightforward in principle — the exchange format maps cleanly to the ontology structure — but it has not been built yet. Until it is, testing against real-world models means hand-authoring RDF, which is not a practical workflow.
SPARQL query libraries for common analysis patterns. The federation queries above work, but they assume the analyst knows SPARQL. A library of named, documented queries for common EA patterns — impact analysis, compliance scope, capability gap analysis, derivation chain traversal — would make the ontology useful to practitioners who are not semantic web specialists. This is planned and has not been started.
Alignment mappings to adjacent vocabularies. TOGAF’s content metamodel, schema.org organizational vocabularies, and the W3C Organization Ontology (org:) all overlap with ArchiMate concepts in ways that are currently unformalized. Mapping these would enable the federated queries shown above to work against existing HR and organizational data sources without requiring those systems to adopt ArchiMate terminology. The mappings are straightforward; the work is in verifying them against both specifications.
Validation against real-world model instances. The SHACL shapes have been validated against synthetic test cases. They have not been tested against production ArchiMate models exported from tools like Archi or BiZZdesign. There will be edge cases.
The ontology is independent and is not an official publication of The Open Group. ArchiMate® is a registered trademark of The Open Group.
If you work in semantic EA, knowledge graph tooling, or linked data and want to collaborate on any of the above — the exchange format importer in particular would benefit from someone who has export files to test against — I’d welcome the conversation.






Leave a comment